如何展示页面的
从一道经典的面试题入手:从用户输入 URL 到页面展示,这中间都发生了什么?
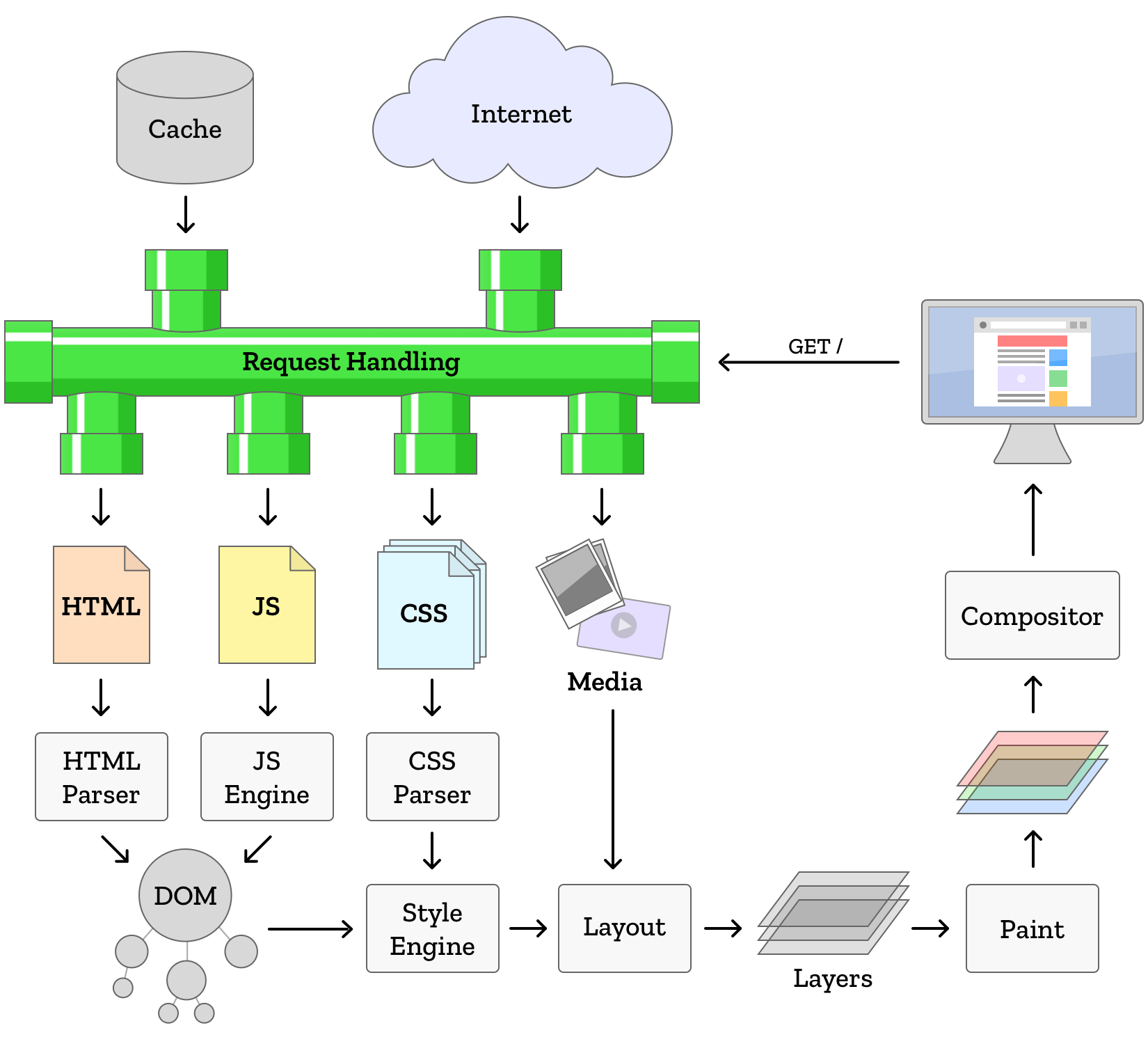
主要分为3个阶段
- HTTP 请求阶段
- 浏览器首先检查本地缓存,如果存在相应资源的缓存并且未过期,可以跳过请求服务器的步骤
- 如果缓存无效,浏览器将根据输入的 URL 解析出协议(通常是 HTTP 和 HTTPS),域名(例如
www.example.com),端口号(HTTP 默认是80,HTTPS 默认是 443) - 浏览器向域名解析服务器发出 DNS 查询请求,将域名解析为服务器的 IP 地址
- 拿到 IP 地址,浏览器将与服务器建立 TCP 连接,这个过程涉及3次握手
- 浏览器发送 HTTP 请求
- HTTP 响应阶段
- 服务器接收到请求后,会根据请求的 URL 和参数来查找或生成响应的资源
- 服务器发送 HTTP 响应
- 浏览器渲染阶段
- 浏览器解析响应体的内容,通常是 HTML 数据
- 浏览器创建 DOM Tree(DOM Tree 是文档对象模型树,是浏览器对页面的内部表示)
- 浏览器加载外部资源,例如 CSS、JS、媒体文件
- 浏览器解析 CSS 并计算每个 DOM 节点的样式,同时创建 CSSOM Tree(CSSOM Tree 是 CSS 对象模型树,即使不提供 CSS,浏览器也有默认样式)
- 浏览器遍历 DOM Tree 并创建 Layout Tree(Layout Tree 是布局树)
- 浏览器遍历 Layout Tree 并创建 paint records(paint records 是对绘画过程的记录,通常顺序是先背景,再文字,后矩形)
- 浏览器遍历 Layout Tree 并创建 Layer Tree(Layer Tree 是层树)
- 浏览器将 Layer Tree 提交给合成器线程 Compositor,合成器线程对每个Layer 进行栅格化,创建合成器帧
- 浏览器将合成器帧发送到 GPU 进程 以在屏幕上显示
- JS 代码在解析和执行的过程可能会修改 DOM Tree 或 CSSOM Tree,这可能触发回流 Reflow 或重绘 Repaint,导致浏览器重新计算布局和重新绘制
JavaScript 可以阻止解析
当 HTML 解析器发现一个 <script> 标签时,它会暂停对HTML文档的解析,并加载、解析和执行 JavaScript 代码。因为 JavaScript 可以使用诸如 document.write() 之类的功能来改变文档的结构,从而改变整个 DOM 结构,因此 HTML 解析器必须等待 JavaScript 运行完毕,然后才能恢复对 HTML 文档的解析。为了提高页面加载性能,通常把 <script> 标签放在 <body> 标签的底部。
如果不希望阻塞页面加载,也可以使用 <script> 标签的 async 和 defer 属性。
- async 表示异步加载和执行,不会阻塞页面的呈现
- defer 表示将在 HTML 文档解析完成后执行